
Quantifizierte Risikoanalyse und CRML – Warum das ein big deal ist
Dieses Wochenende bin ich ziemlich tief ins Thema Risikomanagement eingetaucht. Ich habe mich für die FERMA rimap (Risk Management Professional Certification) registriert, wissenschaftliche Papers gelesen und parallel an CRML (Cyber Risk Modeling Language) weitergearbeitet. Ein paar der Erkenntnisse daraus möchte ich gerne mit euch teilen – wie immer stark vereinfacht (die Quellen verlinke ich).
Die meisten von euch kennen die Formel:
Vulnerability × Threat = Risk
CompTIA hämmert einem das in Security+ regelrecht ein. Und ja, als Einstieg ist das okay. Aber wir alle wissen auch: In der Praxis taugt diese Gleichung nur sehr begrenzt. Sauberes Risikomanagement ist schlicht komplexer.
Es gibt natürlich etablierte Modelle wie OCTAVE Forte oder das FAIR Framework. Ich habe mit beiden gearbeitet – überzeugt haben sie mich ehrlich gesagt nie so richtig.
Der aktuell beste Ansatz (nach meiner Recherche und meiner persönlichen Einschätzung) sind Bayessche Netzwerke bzw. Bayessche Modelle.
Um das einmal möglichst einfach zu erklären:

Stell dir vor, wir werfen eine Münze und sollen beide das Ergebnis raten. Wir wären uns sofort einig: Die Wahrscheinlichkeit für Kopf liegt bei 50 %.
Aber was passiert, wenn wir diese Vorerfahrung nicht haben? Genau das ist ja oft die Realität bei ICT-Risiken: Es gibt wenig oder gar keine belastbaren historischen Daten.
- Ein Bayesscher Ansatz würde sagen: „Ich weiß es nicht. Lass uns erst mal beobachten.“ (Box 1 im Bild links)
- Er wirft die Münze einmal – Kopf. Frequentistisches Ergebnis: aktuell 100 % Kopf. Das Bayessche Bild sieht man links in Box 2.
- Zweiter Wurf: wieder Kopf – 100 % frequentistisch oder Bayessch Box 3.
- Dritter Wurf: Zahl – jetzt liegen wir frequentistisch bei 75 % oder Bayessch beim Bereich in Box 4.
Der entscheidende Punkt: Der Bayessche Ansatz ist sich der Unsicherheit, Varianz und Subjektivität bewusst und benennt deshalb einen Wahrscheinlichkeitsbereich, nicht nur einen Punktwert.
Der Frequentist liefert nach drei Beobachtungen einen Punktschätzer von 75 % – ergänzt um ein sehr breites Konfidenzintervall.
Der Bayessche Ansatz modelliert diese Unsicherheit explizit als Verteilung und vermeidet so eine trügerische Präzision.
Gerade bei wenigen Daten – wie bei ICT-Risiken – ist das realistischer, weil Entscheidungen nicht auf scheinbar exakten Zahlen basieren, sondern auf Unsicherheitsräumen.
Wir wissen aber alle: Je öfter wir die Münze werfen, desto mehr nähern sich beide Modelle der „wahren“ Wahrscheinlichkeit von 50 % an.
Quelle: Probabilistic Programming and Bayesian Methods for Hackers
Okay – wir haben also ein Modell, das für uns sinnvoll ist.
Aber noch ist das alles ziemlich theoretisch.
Tja, hier kommt CRML (Cyber Risk Modeling Language) ins Spiel.
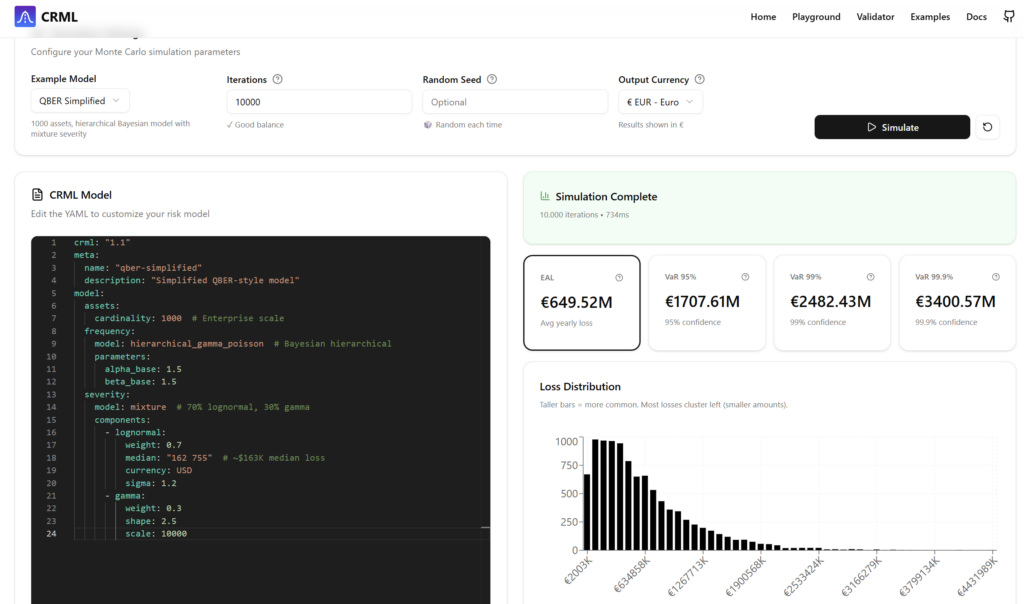
Im Kern geht es darum, Risiken strukturiert zu beschreiben – und zwar in einer maschinenlesbaren, standardisierten Sprache. Das gab es so bisher schlicht nicht.
Genau so, wie die Entwicklung von Terraform IaC ermöglicht hat, soll CRML RaC (Risk as Code) ermöglichen.
Konkret heißt das:
Ich kann Risiken als YAML- oder JSON-Dateien modellieren. Und das eröffnet völlig neue Möglichkeiten.
Ich kann generische Risikomodelle bauen und sie anschließend mit unternehmensspezifischen Daten kalibrieren. Ich kann diese Modelle mit Daten aus bestehenden Tools (z. B. Splunk) füttern. Und ich kann Risiken erstmals sauber zwischen Systemen austauschen.
Wenn sich ein solcher Standard in der Industrie durchsetzt, entsteht eine spannende Vision:
Behörden wie das BSI könnten Modelle oder Datensätze veröffentlichen, die Unternehmen per API nutzen – entweder zur Kalibrierung eigener Modelle oder indem sie die BSI-Modelle mit ihren eigenen Daten anreichern. Der entscheidende Punkt: Risiken werden maschinen-zu-maschine austauschbar.
Wichtig dabei: CRML ist „nur“ eine Sprache. Sie wird von einer Engine interpretiert, die dann z. B. Bayessche Berechnungen durchführt.
Es gibt zwar bereits eine Referenz-Engine, aber ich plane, diese könnte auf Grundlage dieses Papers, dessen Ergebnisse ich sehr überzeugend finde, noch ausgebaut werden.
Die Kernaussage dieses Papers:
Die Auswirkung von Schwachstellen zu modellieren ist oft unnötig – und extrem schwer. Stattdessen schlägt es eine Risikoformel mit drei Parametern vor:
- Auswirkung der Bedrohung
- Wahrscheinlichkeit der Bedrohung
- Wahrscheinlichkeit der Schwachstelle
Das bringt uns einem praktikablen Ansatz deutlich näher.
Die Auswirkung der Bedrohung ergibt sich aus allgemeinen Bedrohungsdaten, z. B. aus Lageberichten, sowie aus Region und Branche der Organisation.
Die Wahrscheinlichkeit der Bedrohung ebenfalls.
Wenn ich nun nur noch die Wahrscheinlichkeit von Schwachstellen brauche – und nicht mehr deren (hoch subjektive) Auswirkungen –, reduziert das massiv den Datenbedarf auf Unternehmensseite. Und genau das macht eine seriöse quantitative Risikoanalyse überhaupt erst realistisch.
Ich hoffe, der Beitrag war interessant. Ich freue mich sehr über Diskussionen und Feedback!
Da ich das ganze Thema super interessant fine, habe ich mich mit Zeron zusammen getan, um kompatible Lösungen auf dem europäischen Markt anzubieten.
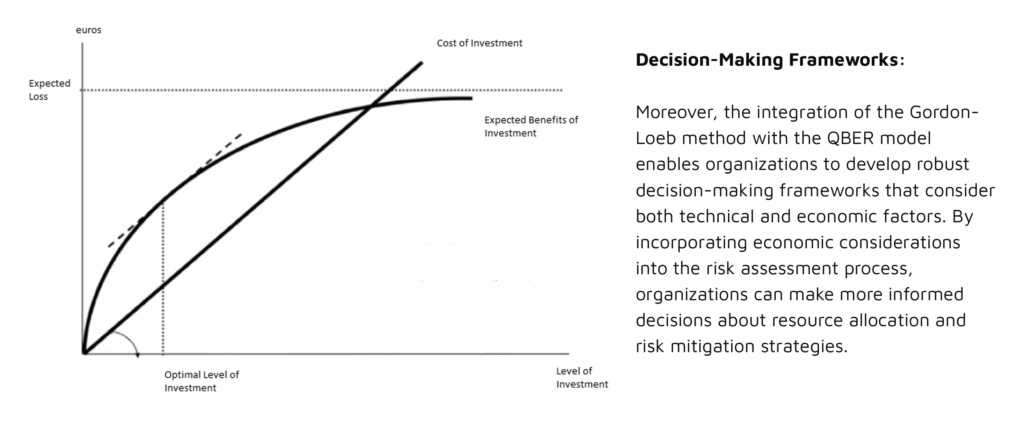
Warum das Ganze? Ist das nicht eine totale Nische?
Ganz ehrlich: Wenn man die 5-Why-Methode anwendet und sich die Root Causes vieler Cybersecurity-Probleme anschaut, landet man fast immer bei demselben Punkt: Unterfinanzierung.
Ich habe bereits das Feedback bekommen, dass ich im Grunde ein Marketing-Tool entwickle – und meinetwegen kann man es auch so nutzen. Mein eigentliches Ziel ist aber ein anderes:
Ich möchte IT-Verantwortlichen ein Werkzeug geben, mit dem sie Geschäftsführung, CFO oder CTO auf Augenhöhe zeigen können, warum sich Investitionen in Sicherheit lohnen – in einer Sprache, die Management versteht.